Google Uses Your Public Internet Data To Train Its ChatGPT Rivals, And You Should Let It

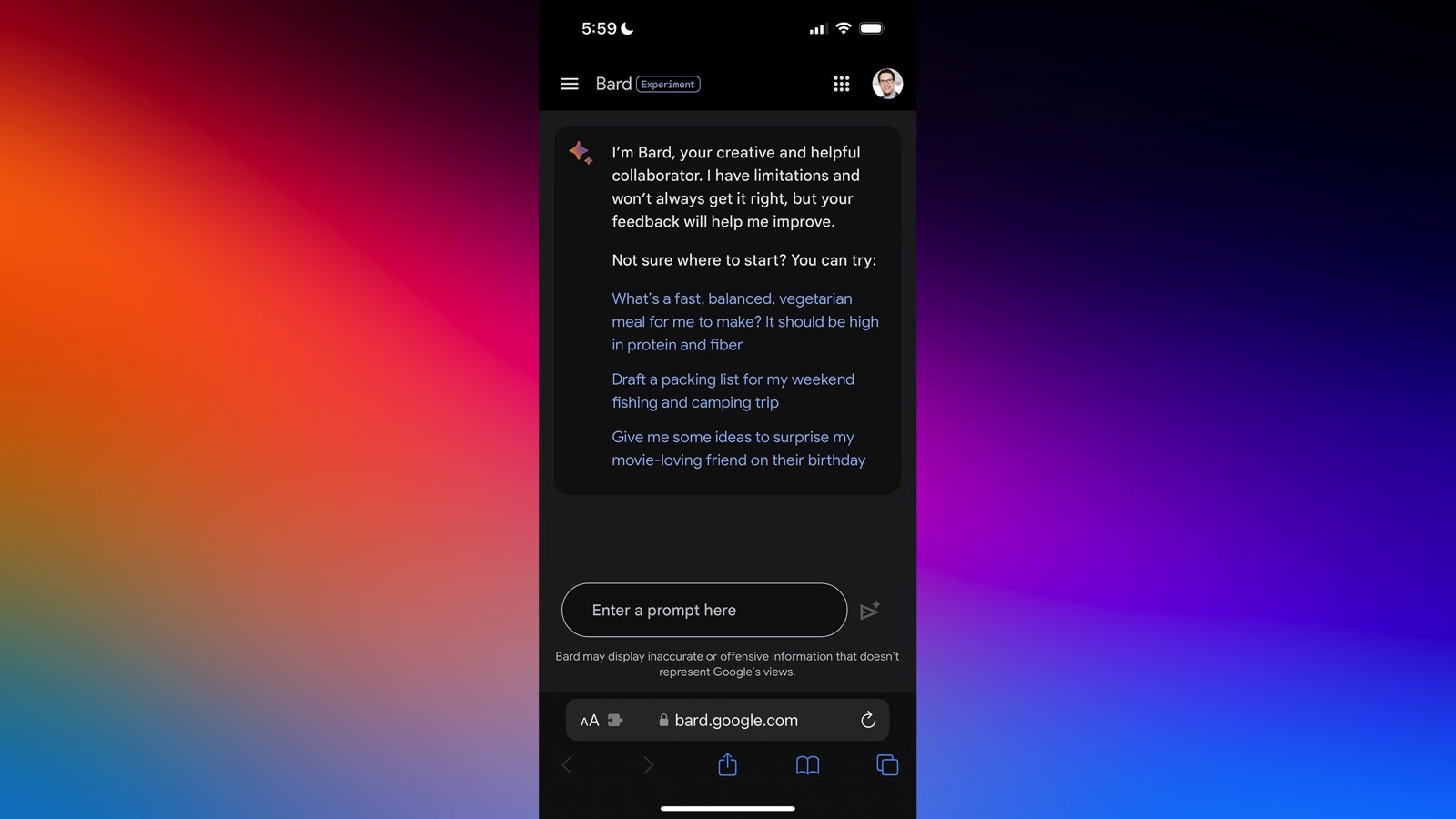
Google might be the first company that comes to mind when thinking about the use of artificial intelligence (AI) in internet software, but OpenAI's ChatGPT is the most popular generative AI product right now. And Google will be remembered for hurrying to respond to ChatGPT rather than leading the market in the early days. Google already has plenty of products that use large language models like ChatGPT, with Bard being one example. And Bard is available right now to test in almost every market.
More importantly, Google just updated its privacy policy to inform users that it'll be using all their data and more to train its ChatGPT rivals. It might seem nefarious, and you might want to opt out. But, ultimately, you'll agree to let Google use that data. Opposing the privacy policy changes basically means ending your relationship with Google. And even then, plenty of your data has already been gobbled up by Google's AI bots.
When OpenAI trained its ChatGPT large language model, it never asked for consent to use the stuff you might have posted publicly in various places on the internet. It didn't do it after the ChatGPT launch either, as it continued to harvest data, including from the prompts you type to the chatbot.
The option to stop your data from reaching OpenAI's servers came down the road in response to the increasing number of ChatGPT privacy and copyright questions that OpenAI started to face.
OpenAI hasn't cleared those hurdles, and there may come a day when it will be held accountable for how it trained ChatGPT. The company basically ignored user privacy and copyright to train its AI, and that might be the only way to get a product as sophisticated as ChatGPT out the door.
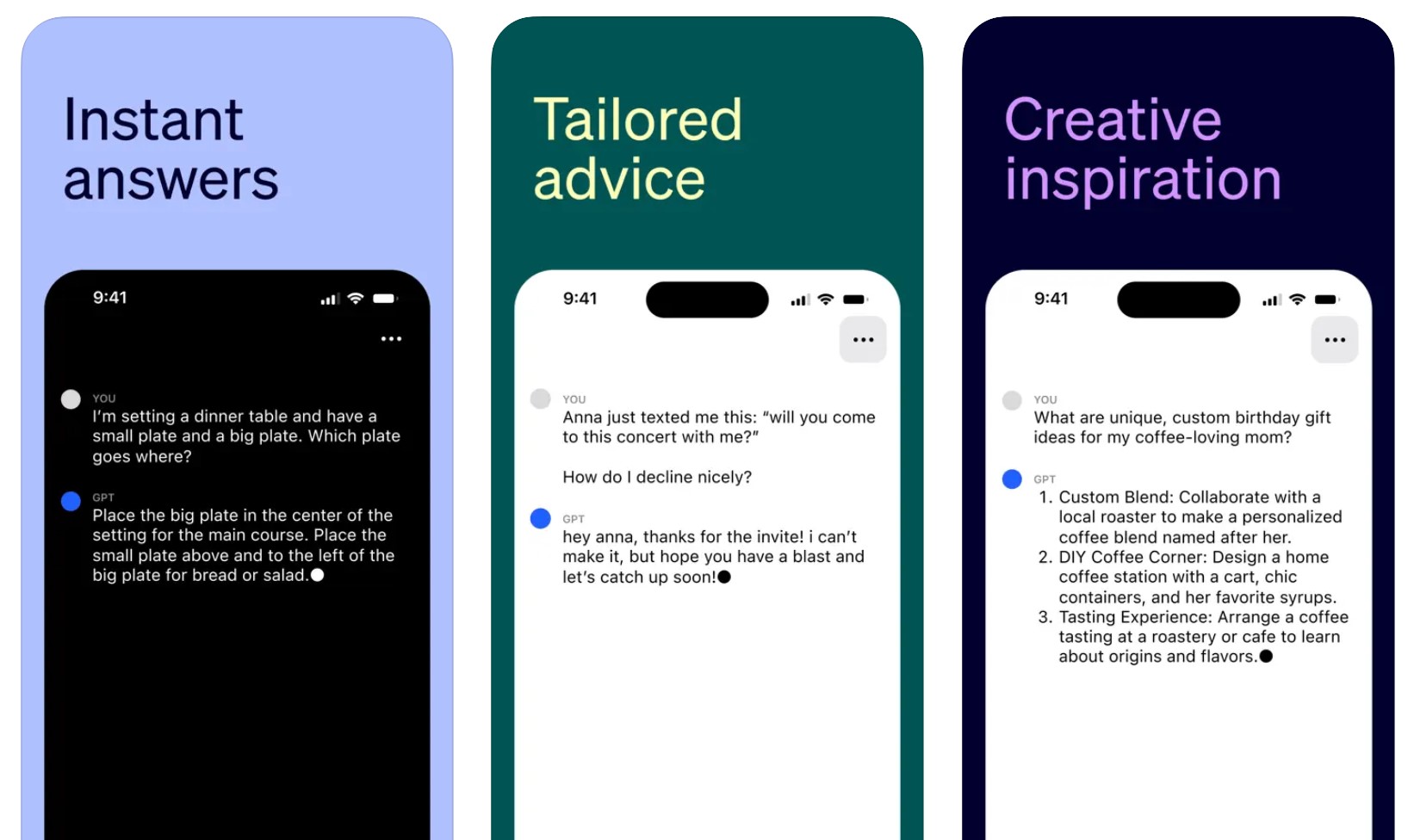
That's probably why Google is changing its privacy policy to reflect the need to collect as much data as possible for Bard, SGE, Gemini, and who knows what other generative AI product it might be working on.
It's still a better take than OpenAI, but the comparison isn't fair. It's not like billions of people used OpenAI's products when the company developed ChatGPT. So OpenAI never had to worry about the privacy implications, as Google does.
Billions of people do use Google products, so the company has a bigger challenge at hand in training its generative AI products. Google has to implement some sort of privacy policy to govern those products. And I will remind you that Google Bard isn't officially available in the entire European Union because of privacy issues.
As Gizmodo observed, Google changed its privacy policy over the weekend. The updates reflect its need to collect as much user data from the public internet. That includes everything you post online publicly and stuff that has nothing to do with Google products.
Here's the "Research and development" fragment from Google's privacy policy:
Research and development: Google uses information to improve our services and to develop new products, features, and technologies that benefit our users and the public. For example, we use publicly available information to help train Google's AI models and build products and features like Google Translate, Bard, and Cloud AI capabilities.
Previously, the section mentioned "language models" rather than "AI models." It also mentioned only products like Google Translate, whereas it now lists Bard and Cloud AI.
Moreover, the privacy policy's wording indicates that Google will grab data from anywhere on the internet as long as it's publicly available.
Again, ChatGPT did the same thing, and OpenAI's training procedure already impacted how the internet works. Reddit made big changes to how third-party apps and companies can use its API to read data on the website. This sparked a massive backlash from Redditors, but the company blamed ChatGPT for it.
Twitter last weekend restricted access to tweets, with Elon Musk also pointing the finger at generative AI like ChatGPT. However, unlike Reddit, Twitter has plenty of Musk-made problems, and ChatGPT scraping data is probably the least of its worries.
Still, this shows that internet companies are paying attention to how the public data available on their services is used by ChatGPT and competitors. Google is looking to take advantage of that data for free while it still can. No one knows what might come down the road, especially regarding AI regulatory pressure.
As such, you will probably agree to Google's privacy changes. Just like I will. Most people will not bat an eye at the changes. It's all public data anyway; it's already available for everyone to see on the internet. But that doesn't necessarily make it okay. Nor should we ignore what has just happened while we witness the creation of the computers and internet of the future.
There's no real way to prevent ChatGPT, Bard, and any other generative AI product from feeding off your digital data that's out in the public.
What will be more important is protecting personal data that's not public from chatbots. And that includes the prompts we use to talk to bots like ChatGPT and Bard.