This AI Is As Good As ChatGPT o1, And It Was Built For Under $50
DeepSeek R1 stunned the world last week as its developers explained they could train an open-source reasoning AI as good as ChatGPT o1 at a fraction of the cost. Suddenly, anyone could create powerful AI models with the right combination of software innovations and decent hardware. The DeepSeek research implied that the focus wouldn't be on high-end hardware anymore, and this tanked get AI tech stocks like NVIDIA.
As we now know, however, that's not exactly the case. The DeepSeek software innovations, as interesting as they might be, do not tell the whole story. In the days following the R1 release, we learned that DeepSeek might have used ChatGPT answers to train its AI. OpenAI accused the Chinese company of distilling its ChatGPT models themselves. Separately, we saw indirect evidence that suggests DeepSeek is indeed based on outputs from ChatGPT.
This indicates that DeepSeek circumvented development costs by potentially pulling from competitor AIs that were already established. As the full picture formed, the stock market recovered most of its losses.
I'm telling you all this because I'm about to show you an equally mind-blowing experiment. Researchers at Stanford and the University of Washington trained a reasoning AI called S1 that's as good as ChatGPT o1. They did it for just $50 in compute costs using the same DeepSeek twist. They distilled a version of Gemini and used an open-source AI from China.
The S1 research paper explains how it was all possible, and before you ask, no, this won't tank the stock market again. That is, it shouldn't do it. The point of this research is to show that it could be even cheaper to train high-end AIs using new software innovations, but only after someone has developed cutting-edge frontier AIs that can be used for distillation.
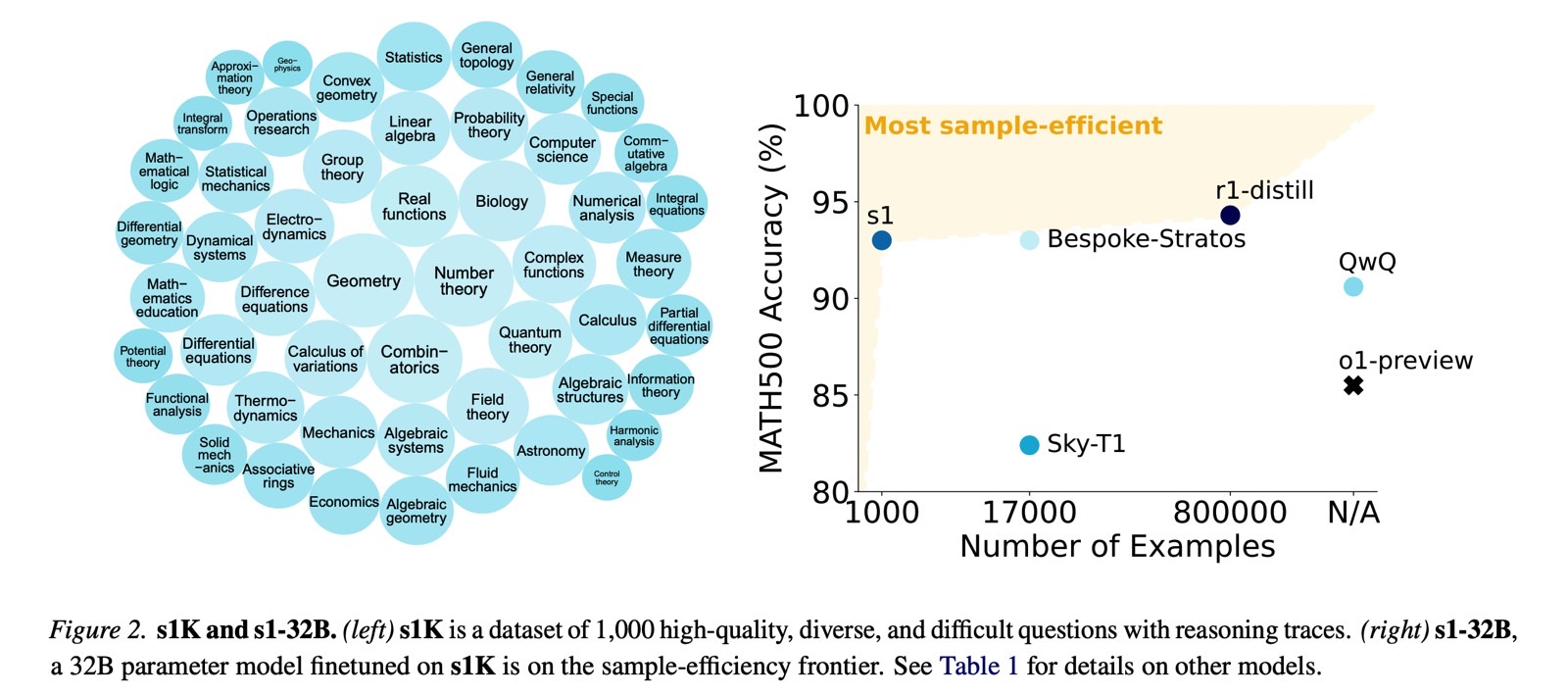
The researchers went to Google to use Gemini 2.0 Flash Thinking Experimental, an already established AI, to generate a set of 1,000 high-quality reasoning questions. The reasoning steps and responses were then used to train the s1-32B model, which was based on an open-source Qwen model from Chinese giant Alibaba.
The researchers needed less than 30 minutes to train S1 using the Gemini-distilled data (the 1,000 prompts). After that, the S1 was already displaying high scores in AI benchmarks. The model actually outperformed o1-preview by 27% on competition math tasks.
A Stanford engineer told TechCrunch he could rent the necessary compute today for about $20.
The researchers devised various other innovations to train the S1 reasoning model to match the abilities of ChatGPT o1. They focused on allocating more compute to the model during inference or when the AI is formulating its response.
Also important is the use of a "wait" token during the reasoning part, which helps S1 reach a more accurate conclusion. The "wait" trick can improve responses and further reduce costs.
The S1 paper will unlikely make as many waves as DeepSeek R1 did, but it's probably just as important. This opens the door to a new wave of AI models that can be as powerful as the likes of ChatGPT, Gemini, DeepSeek, and others without costing as much.
While the cost is misleading because the model uses a distillation of a more advanced AI, it still is an important breakthrough other AI firms might take advantage of.

I said last week that DeepSeek R1 could offer Apple ideas on how to make Apple Intelligence more powerful while processing remains on-device. The S1 technique could be equally important.
But I'll say again that AI breakthroughs like R1 and S1 should not prevent the top competing AI firms from investing more money in compute.
High-end hardware will be needed to create the next big AI models on the road to AGI. OpenAI, Google, and all the big names in AI tech will continue to come up with better models that will cost millions of dollars to train. In turn, smaller AI teams, like the S1 researchers, will find ways to fine-tune those AIs, where they can, to obtain incredibly powerful AI models that have specific use cases in mind.
The S1 model is available on GitHub. The research can be found at this link.