Nvidia Stunned The World With A ChatGPT Rival That's As Good As GPT-4o

You can't talk about generative AI software like ChatGPT without thinking of Nvidia, which is one of the big winners of the early days of the genAI revolution. But Nvidia is best known so far for providing the chips that companies like OpenAI need to process all of their complex generative AI functions.
Fast-forward to early October 2024, and Nvidia stunned the AI world by announcing NVLM 1.0, a family of large multimodal language models that can perform at least as well as ChatGPT's GPT-4o model.
Before you get too excited about Nvidia's potential consumer-facing NVLM product, you should know the company is choosing a different avenue to show its genAI strength. Rather than releasing a direct rival to ChatGPT, Claude, and Gemini, it's making the model weights publicly available so others can use NVLM to develop their own AI apps and systems.
Nvidia released a paper to announce NVLM 1.0 and reveal it's going to open-source the weights and training code:
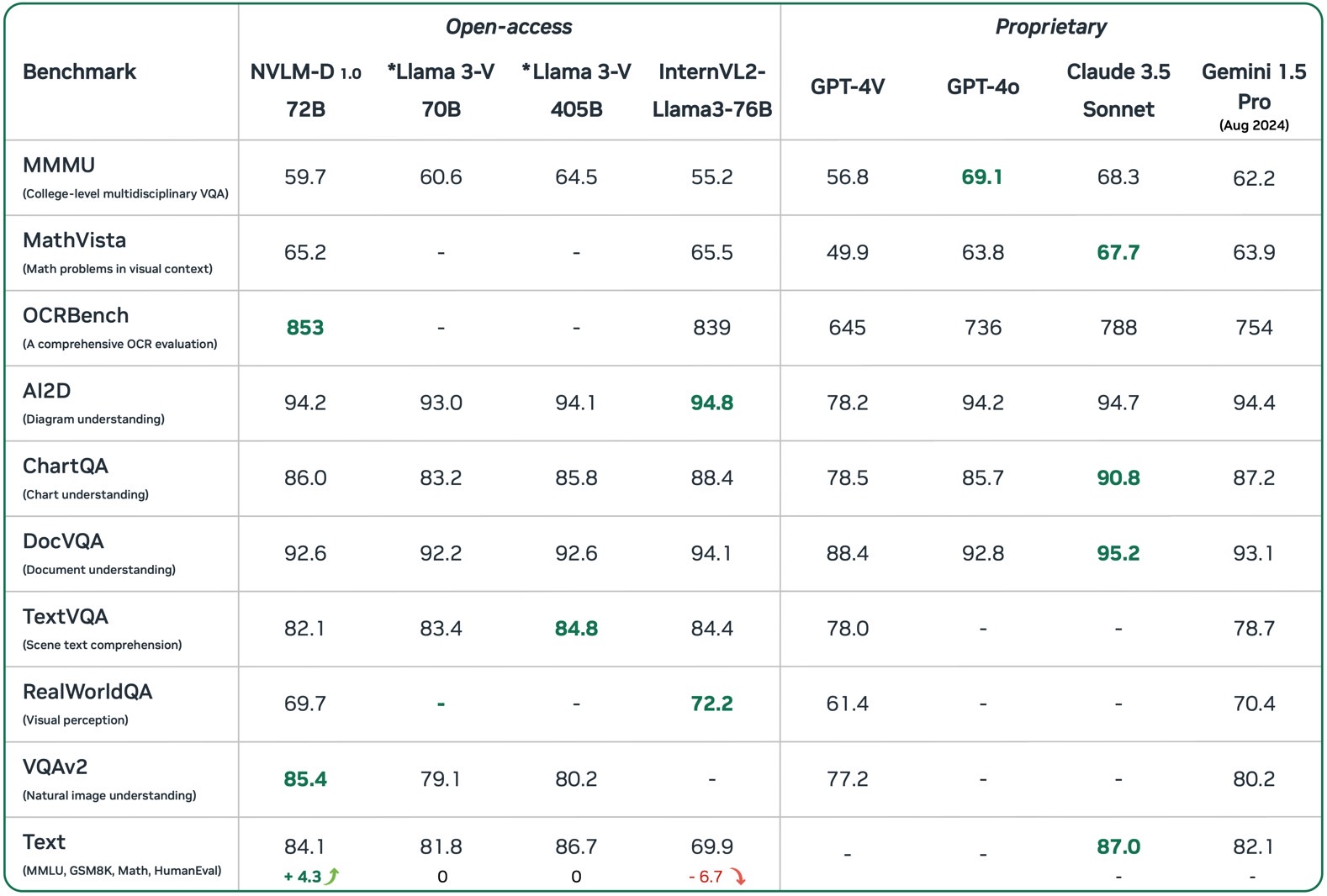
We introduce NVLM 1.0, a family of frontier-class multimodal large language models (LLMs) that achieve state-of-the-art results on vision-language tasks, rivaling the leading proprietary models (e.g., GPT-4o) and open-access models (e.g., Llama 3-V 405B and InternVL 2). Remarkably, after multimodal training, NVLM 1.0 shows improved accuracy on text-only tasks over its LLM backbone. We are open-sourcing the model weights and training code in Megatron-Core for the community.
The 72 billion parameter NVLM-D-72B is Nvidia's flagship LLM. The company says it "achieves performance on par with leading models across both vision-language and text-only tasks."
The paper shows various chat examples that involve multimodal input. The humans in the chats use text and images in their prompts. The examples show that the AI is very good at identifying people, animals, and objects in these images and providing answers related to them.

In the example above, the user asks NVLM to explain a meme, and the AI does it exceptionally well. Here's Nvidia's explanation for the AI's abilities:
Our NVLM-D-1.0-72B demonstrates versatile capabilities in various multimodal tasks by jointly utilizing OCR, reasoning, localization, common sense, world knowledge, and coding ability. For instance, our model can understand the humor behind the "abstract vs. paper" meme in example (a) by performing OCR to recognize the text labels for each image and using reasoning to grasp why juxtaposing "the abstract" — labeled with a fierce-looking lynx — and "the paper" — labeled with a domestic cat — is humorous.
NVLM can also solve complex math problems, something we've seen with other genAI products, including OpenAI's ChatGPT.
Also, Nvidia says NVLM-D-72B can improve performance on text-only tasks after multimodal training.
The benchmarks Nvidia offered indicate that NVLM can more than hold its own against GPT-4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro. Nvidia's now-open genAI language model can actually outpefrom the proprietary AI products from OpenAI, Anthrophic, and Google in certain tasks. The table below also shows that NVLM-D-72B is on par with open-access Llama AI platforms from Meta.
As VentureBeat points out, Nvidia's surprise reveal has stunned some AI researchers.
It's not just the performance of NVLM, but Nvidia's decision to make it available as an open-source project. The likes of OpenAI, Claude, and Google aren't expected to do that anytime soon. Nvidia's approach could benefit AI researchers and smaller firms, as they'd get access to a seemingly powerful multimodal LLM without having to pay for it.
Wow nvidia just published a 72B model with is ~on par with llama 3.1 405B in math and coding evals and also has vision 🤯 pic.twitter.com/c46DeXql7s
— Phil (@phill__1) October 1, 2024
Regular ChatGPT users like you and I will have to wait and see what comes out of Nvidia's announcement. That is, we'll have to wait for commercial products that utilize NVLM. The sooner that happens, the better for the industry, as it might impact the various business decisions of OpenAI, Anthropic, Google, and others.