ChatGPT Safety Researcher Quits, Says He's 'Pretty Terrified' Of The Speed Of AI

These days, the AI news cycle is dominated by DeepSeek. DeepSeek is a Chinese startup that released a reasoning model as powerful as ChatGPT o1 despite not having the massive hardware and infrastructure resources of OpenAI. DeepSeek used older chips and software optimizations to train DeepSeek R1.
Accusations from OpenAI that DeepSeek might have distilled ChatGPT to train precursors of R1 don't even matter.
The DeepSeek project probably achieved its goal on multiple fronts. It leveled the playing field in the AI wars, giving China a fighting chance. DeepSeek also gave a huge financial blow to the US stock market, which lost nearly $1 billion, with AI hardware companies accounting for the biggest market cap losses.
Finally, DeepSeek gave China a software weapon that might be even more powerful than TikTok. DeepSeek is the number one app in the App Store. On top of that, anyone can install the DeepSeek model on their computer and use it to build other models.
With all that in mind, you might not even pay attention to reports saying that another key OpenAI safety researcher has quit. Steven Adler is another name we'll add to a growing list of engineers who left OpenAI in the past year.
It's also interesting that the engineer quit in mid-November but made his departure public on Monday, just as DeepSeek news crashed the market.
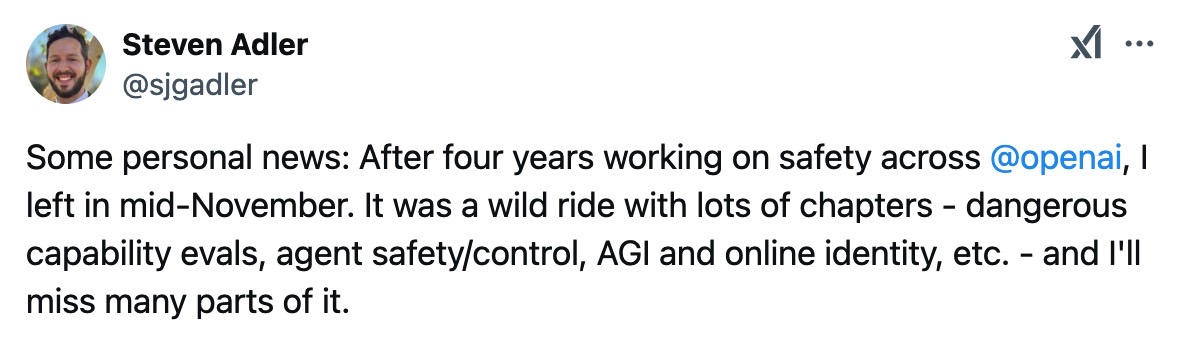
Adler said on X that he's quitting the company after four years. "It was a wild ride with lots of chapters – dangerous capability evals, agent safety/control, AGI and online identity, etc. – and I'll miss many parts of it," he said before dropping a bleak statement.
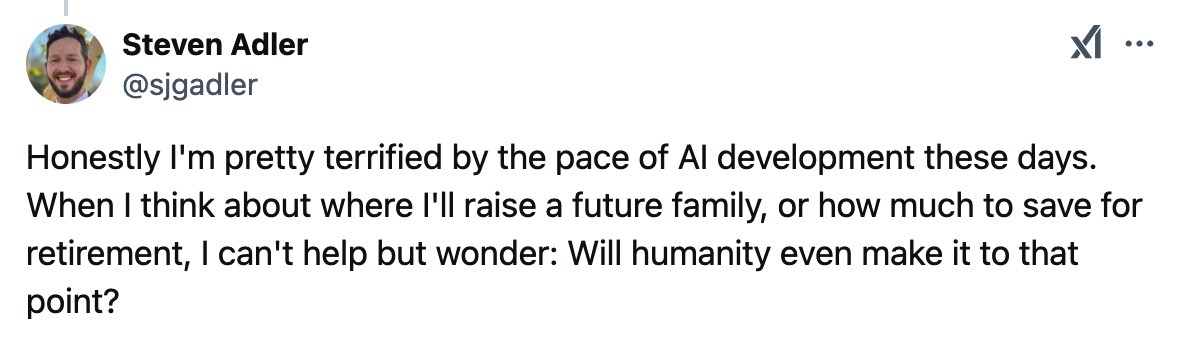
The researcher said he's "pretty terrified by the pace of AI development these days." Adler's remark echoes the fears of other AI experts who think AI will bring our inevitable doom. The former ChatGPT safety researcher didn't mince words, saying he's worried about the future.
"When I think about where I'll raise a future family or how much to save for retirement, I can't help but wonder: Will humanity even make it to that point?" he asked.
I'd be curious to hear what Adler saw at OpenAI that made him leave the company. I'd be even more curious to hear why he didn't stick around to potentially help save humanity from bad AI by being involved in one of the most important AI firms out there.
Adler might have been witnessing AGI (artificial general intelligence) research at OpenAI, something the company is clearly developing. I'm speculating here, but it's based on a follow-up tweet. Adler said, "AGI race is a very risky gamble, with huge downside. No lab has a solution to AI alignment today. And the faster we race, the less likely anyone finds one in time."

Presumably, OpenAI is speeding in that AGI race. AGI is the kind of AI that will match the creativity and ability of a human when tasked with trying to solve any problem. But AGI will also hold much more information, so it can address any task much better than a human. At least that's the idea.
Alignment is the most important safety matter concerning AI, AGI, and superintelligence (ASI). AI has to be aligned with humanity's interests at all levels. That's the only way to ensure AI will not develop agendas of its own that might lead to our demise.
However, real-life products like ChatGPT and DeepSeek already give us two types of alignments. ChatGPT is, hopefully, aligned with US and Western interests. DeepSeek is built with Chinese interests first, and it's aligned with those via censorship.

Adler also seemed to refer to DeepSeek in his Monday thread on X without naming the Chinese startup.
"Today, it seems like we're stuck in a really bad equilibrium," he said. "Even if a lab truly wants to develop AGI responsibly, others can still cut corners to catch up, maybe disastrously. And this pushes all to speed up. I hope labs can be candid about real safety reas needed to stop this."
How is this tied to AI? Well, the DeepSeek R1 open-source model is available to anyone. Nefarious actors with some resources, know-how, and new ideas might stumble upon AGI without knowing what they're doing or even realizing they'd unleash a superior form of AI onto the world.
This sounds like a sci-fi movie scenario, sure. But it might happen. It's just as valid as a scenario like, say, a big AI firm developing AGI and ignoring the warnings of safety researchers, who eventually end up leaving the firm one by one.
It's unclear where Adler will move next, but he appears to be still interested in AI safety. He asked on X what people think the "most important and neglected ideas in AI safety/policy" are, adding that he's excited about "control methods, scheming detection, and safety cases."