How Google Photos Tells The Difference Between Dogs, Cats, Bears, And Any Other Animal In Your Photos
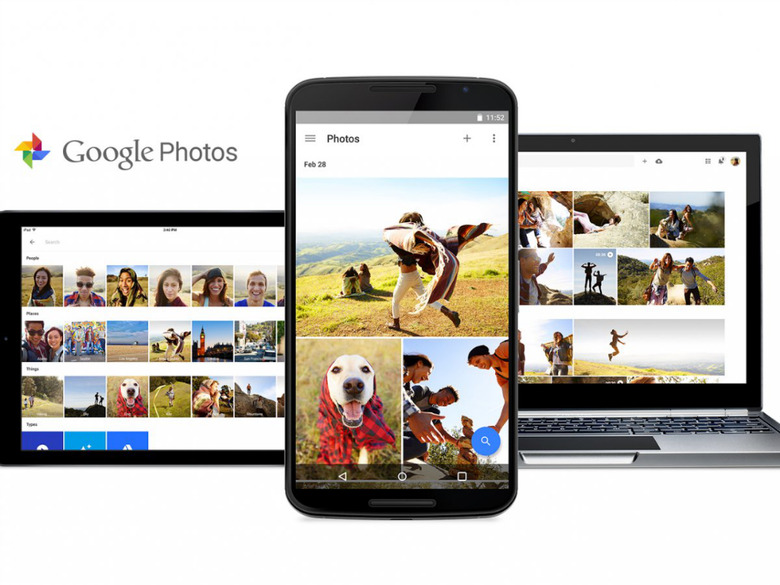
Google at its I/O developer conference last week took the wraps off of Google Photos, the company's new photo software that provides users with unlimited cloud storage for both photos and videos. Of course, unlimited storage is just one of many reasons why Google's exciting new photo sharing service is poised to make quite a splash.
Leveraging Google's expertise in machine learning, Google Photos can smartly organize your photos based on categories such as people, places, and things. Google is able to do this by combining its facial recognition software with information gleaned from geo-tagged photos. But what's even more impressive is that Google has developed software capable of recognizing "things."
DON'T MISS: What Tim Cook and Apple don't get about Google's success: Consumers don't value their privacy
"But the Things section, while less accurate, is more impressive," Walt Mossberg writes for Re/Code. "Here, the app uses cloud computing power to aggregate shots of, say, flowers or cars or the sky or tall buildings or food or concerts, graduations, birthdays — and yes, cats."
And speaking of cats, Google Photos can impressively tell the difference between dogs, cats, and any number of other animals you might think of throwing at it. While facial recognition on humans is one thing, applying such software to varying species is an entirely new challenge altogether.
While Google briefly touched on how it accomplishes this during I/O, a recent article in Medium delves a bit deeper into the layered approach Google implements in order to tell different animals and objects apart.
To begin with, Google's software views each photo as having a distinct number of varying layers. Each layer contains different information about the photograph in question.
If the input is a picture of a cat..., then the first layer spots simple features such as lines or colors. The network then passes them up to the next layer, which might pick out eyes or ears. Each level gets more sophisticated, until the network detects and links enough indicators that it can conclude, "Yes, this is a cat." The 22 layers are enough to tell the difference between, say, "wrestle" and "hug" — two abstract concepts with minute visual differences that might confuse a network with fewer layers.
Additionally, Google is also able to leverage what it's learned over the years with traditional image searches on its search engine. Specifically, because Google has learned what type of images are closely associated with queries like "dogs" and "cats", it has "trained the Photos neural network to associate the word 'cat' with strong cat indicators" and so on and so forth.
While it all sounds simple in theory, there's a tremendous amount of impressive Computer Science going on behind the scenes. Of course, the beauty is that the end user is completely oblivious to all of the complex algorithms running in the background. All users have to do is search for "Dogs" and Google can take care of the rest.
Make sure to hit the source link below for a more detailed explanation as to how Google Photos' algorithm runs. It's really quite fascinating.